Concat
Introduction
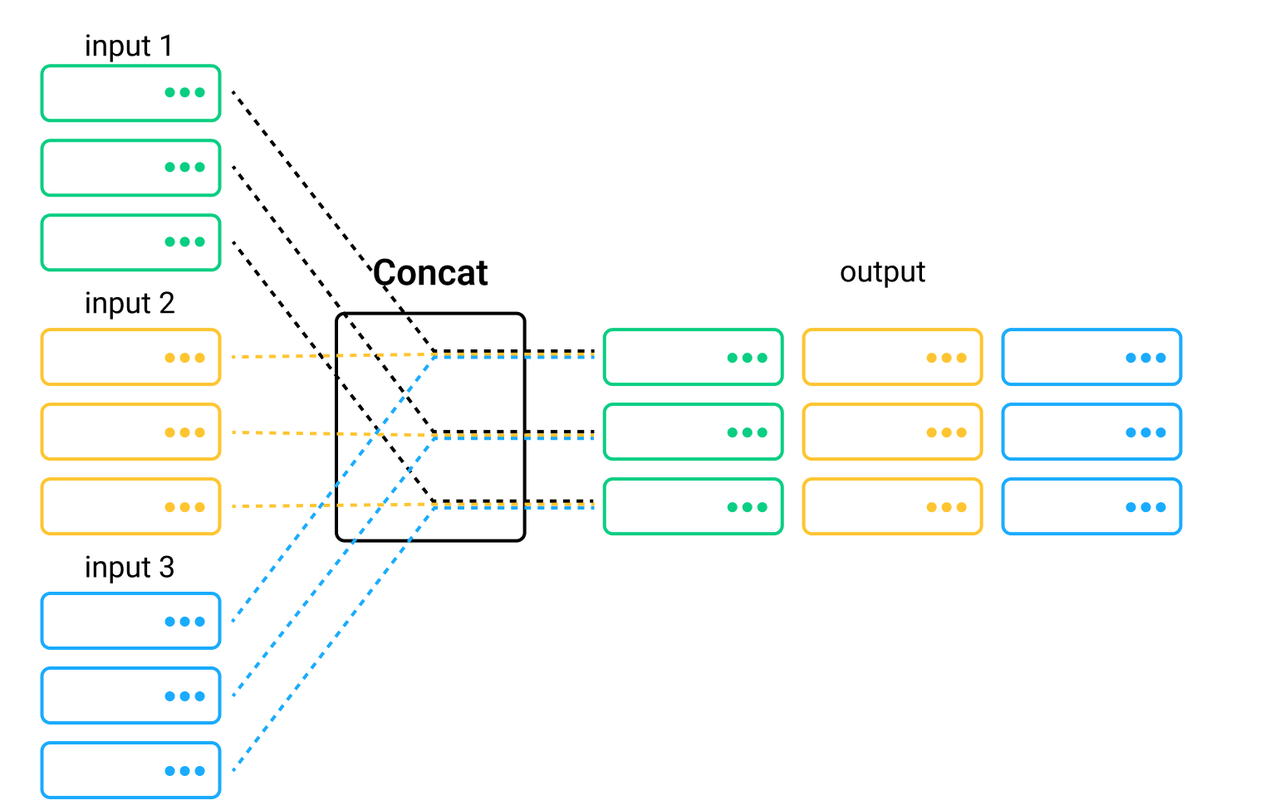
A concat node concats multiple pipelines' intermediate results, and groups all the pipelines into a bigger one.
The concat node does not apply functions for data processing. Instead, this node only merges the outputs of multiple pipelines. Refer to concat API for more details.
Example
We use the concat(*pipeline) interface to create a concat node. If the columns in different pipelines share the same column name, the concat node will overwrite the data in the columns according to the order of the pipelines. In addition, the concat node requires the multiple pipelines to derive from the same input. In other words, the DAG of a bigger pipeline merged from several pipelines has only one input and one output node.
Now let's take an example pipeline to demonstrate how to use a concat node. This pipeline has a concat node and can extract the feature embeddings of two streams of multi-modal data - images and image captions.
from towhee import pipe, ops
in_pipe = pipe.input('url', 'text')
img_embedding = (
in_pipe.map('url', 'img', ops.image_decode.cv2_rgb())
.map('img', 'img_embedding', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='image'))
)
text_embedding = in_pipe.map('text', 'text_embedding', ops.image_text_embedding.clip(model_name='clip_vit_base_patch16', modality='text'))
img_text_embedding = (
img_embedding.concat(text_embedding)
.output('img', 'text', 'img_embedding', 'text_embedding')
)
img = 'https://towhee.io/object-detection/yolov5/raw/branch/main/test.png'
text = 'A dog looking at a computer in bed.'
res = img_text_embedding(img, text)
The DAG of the img_text_embedding pipeline is illustrated below:
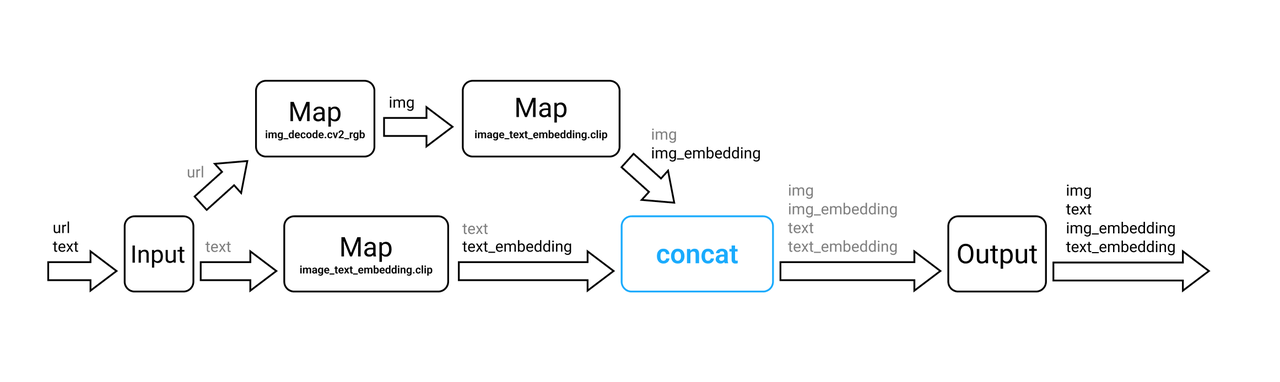
The data processing workflow of the main nodes is as follows.
The image embedding part:
- Map: Uses the image-decode.cv2-rgb operator to decode image URLs (
url) into images (img). - Map: Uses the image_text_embedding/clip operator to extract feature embeddings (
img_mbedding) of the images. The initialized parameter of the operator ismodel_name='clip_vit_base_patch16', modality='image'. This means using the clip_vit_base_patch16 model to extract feature embeddings, and the modality isimage.
The text embedding part:
- Map: Uses the image_text_embedding/clip operator to extract the feature embeddings (
text_embedding) of image captions (text). The initialized parameter of the operator ismodel_name='clip_vit_base_patch16', modality='text'. This means using the clip_vit_base_patch16 model to extract feature embeddings, and the modality istext.
The concat part:
- Concat: Merges the above two pipelines. In other words, this node merges images (
img), texts (text), image embeddings (img_mbedding), and text embeddings (text_embedding) into one table and returns this table as the ouput.
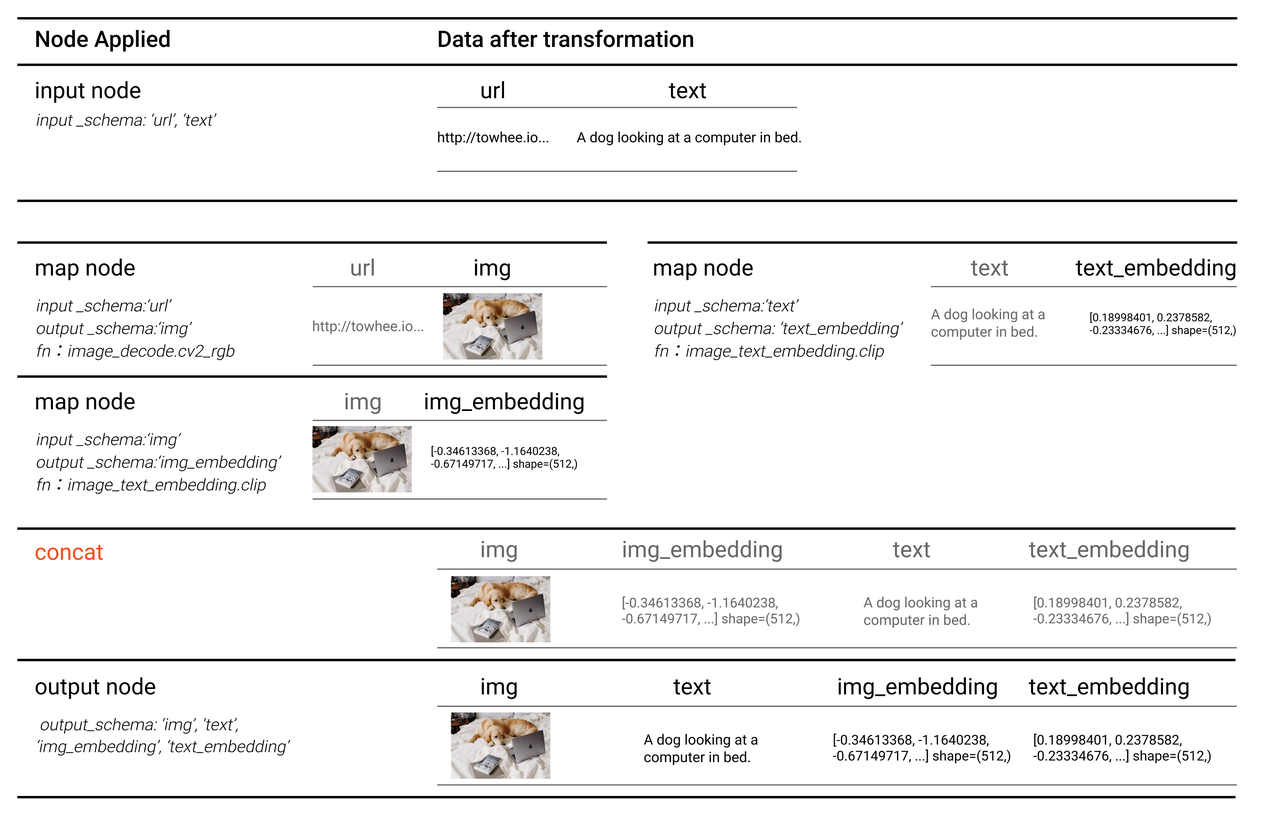
When the pipeline is running, data transformation in each node is illustrated below.
Note:
- The data in the
imgcolumn are in the format oftowhee.types.Image. These data represent the decoded images. For easier understanding, these data are displayed as images in the following figure.
Notes
- If the columns in multiple upstream pipelines share the same column name, the concat node will overwrite the data in the columns according to the order of the pipelines.
- The concat node requires the upstream pipelines to derive from the same input. The DAG of a bigger pipeline has only one input and one output node.